Automating Wordle
It’s been a weird day.
Erin’s family has recently been into a word game called Wordle. Inevitably it spilled into Erin’s life, and subsequently into mine. The rules are simple: there’s a secret five-letter word, and you need to find it by guessing words. If your word shares a letter in the same place as the secret word, that letter is marked as green. If you have a letter in a different place, but also in the secret word, it’s marked as yellow.
The goal is to find the secret word in six guesses or fewer. Yesterday’s, for example, was “pilot.”
After two days of doing it by hand, like a damn pleb, I decided it would be more fun to try to automate this game. So I spent all day thinking about how to do it, and eventually came up with a nice strategy. This blog post documents it, taking time to explain how it works, and more importantly, why.
Measuring Information
The trick to Wordle is to extract as much information from your guesses as possible. But what does it mean to “extract” information? Is information something we can put a number on?
Rather surprisingly, the answer is yes.
Let’s illustrate the idea by ignoring Wordle for a moment. Instead, imagine I have a buried treasure, somewhere on this map:

You don’t know where the treasure is, but you can ask me some yes/no questions, and I promise to answer truthfully. In six questions, can you find the treasure?
The trick here is to be very strategic about how you ask your questions. For example, the first question you ask might be “is the treasure on the left half of the map?”, to which I reply yes. We can now redraw the map, using red to highlight the places the treasure could still be:
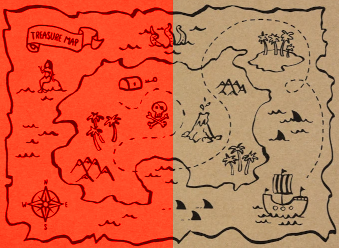
Next you can ask “is the treasure on the bottom half of the remaining red region?” I say no. Thus the treasure is on the top half, and our refined map looks like this:
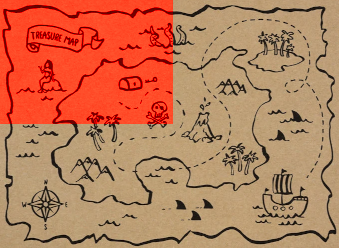
“Is the treasure on the right half?” Yes.

“Top?” No.

You get the idea. By phrasing subsequent questions like this, each time we cut in half the remaining possible hiding spots for the treasure. When we find the treasure, we’re done.
To quantify the amount of information necessary to find the treasure, we need only count how many questions we asked. If we can go from the full map to finding the treasure in 7 questions, we say we needed 7 bits of information to find it.
In general, the information required to solve a problem is the number of times we need to split the space in half in order to find what we were looking for. Information is measured in “bits.”
Back To Wordle
How does any of this apply to Wordle? The first question to ask ourselves is just how much information is required to win the game. But what does that mean? We’re trying to find one particular five-letter word in the entire English language. So, how many five-letter words are there in the English language? Nobody knows for sure, but I wrote a program to look through the dictionary, and it came up with 5150 words.
If we need to find one word in particular out of these 5150, how many times do we need to cut it in half? Let’s do the math:
5150 / 2
= 2575 / 2
= 1288 / 2
= 644 / 2
= 322 / 2
= 161 / 2
= 81 / 2
= 41 / 2
= 21 / 2
= 11 / 2
= 6 / 2
= 3 / 2
= 2 / 2
= 1Thirteen cuts! It takes thirteen cuts to trim down the search space of all possible Wordle words down to a single word. Thus, analogously to our hidden treasure, we need thirteen bits of information in order to find the secret word.
Discovering Information
Knowing the amount of information necessary to solve Wordle is one thing, but where does that information actually come from? Recall, the rules of the game don’t even let us ask yes or no questions; all we’re allowed to do is guess a five-letter word.
How can we turn a five-letter word into a yes/no question? Much like with the buried treasure, it helps to have a lay of the land. Imagine that by some chance, exactly half the words in the dictionary had an e in them, and the other half had no e. Then, by guessing a word that contains an e, we could narrow down the possible words by half depending on whether or not we got a yellow result from Wordle.
Imagine by another coincidence that exactly half the words in the dictionary had an s in them, and the other half didn’t. We could further refine our possibilities by guessing a word that has an s as well as an e.
So that’s the idea. Of course, no letter is going to be in exactly half of the words, but some will be more “exactly half” than others. We can inspect the dictionary, and find the letters which are most “balanced.” Doing that, we get the following:
e: 203
a: 497
r: 641
o: 969
t: 981
l: 1019
i: 1021
s: 1079
n: 1215
u: 1401
c: 1419
y: 1481
h: 1557
d: 1575
p: 1623
g: 1715
m: 1719
b: 1781
f: 1901
k: 1911
w: 1927
v: 2017
x: 2241
z: 2245
q: 2257
j: 2261The numbers here measure the imbalance of each letter. That is, there are 203 fewer words that contain e than do not. On the other end, there are 2261 more words that don’t contain j than do. This means that by guessing e, we are going to get a much more even split than by guessing j.
The letters with lower numbers give us more information on average than the letters with big numbers. And remember, information is the name of the game here.
By forming a five-letter word out of the most-balanced letters on this list, we can extract approximately five bits of information from the system. So that means we’d like to come up with a word from the letters earot if at all possible. Unfortunately, there is no such word, so we need to look a little further and also pull in l. Now we can make a word from earotl—later!
Since later is formed from the most balanced letters in the word set, it has the highest expected information. By trying later first, we are statistically most likely to learn more than any other guess.
Let’s see how it does against yesterday’s word pilot. We get:
🟨⬛🟨⬛⬛
No greens, but we know that the secret word (pilot) doesn’t have any as, es or rs. Furthermore, we know it does have both a l and a t. Therefore, we can eliminate a huge chunk of our words, for example:
titanbecause the secret word has noacupidbecause it doesn’t have anl
and, as you can imagine, lots of other words.
In fact, the number of words remaining is 27. They are:
blitz,blunt,built,cloth,clout,filth,flint,flout,glint,
guilt,hotly,light,limit,lofty,lusty,moult,pilot,quilt,
sloth,spilt, split,still,stilt,stool,tulip,unlit,untilWe can check how many bits of information we extracted:
log2 (5150 / 27) = 7.58We managed to extract nearly 8 bits of information from this one guess! That’s significantly better than the 5 we should have gotten “theoretically.” Not bad at all!
Our next guess can be found in the same way. Take the 27 remaining words, and figure out which letters are best balanced among them:
u: 5
i: 7
o: 9
s: 13
h: 17
n: 17
f: 19
p: 19
b: 21
g: 21
y: 21
c: 23
m: 23
q: 25
z: 25
a: 27
d: 27
e: 27
j: 27
k: 27
l: 27
r: 27
t: 27
v: 27
w: 27
x: 27Notice that several letters have an unbalanced count of 27. This means either all the words have (or do not have) this letter, and thus, these are completely unhelpful letters to guess.
Of our remaining 27, the most balanced word we can make from these letters is until. But notice that until uses both t and l, which we already learned from later!
We can do better by picking a word from the original dictionary which is most balanced according to these numbers. That word is using. Let’s use it for our next guess, which results in:
⬛⬛🟨⬛⬛
We’re left with only four words:
blitz,filth,limit,pilotRinse and repeat, by finding the most balanced letters in the remaining possibilities, and then finding the best word in the dictionary made out of those letters. The next guess is morph:
⬛🟨⬛🟨⬛
Which eliminates all words except for pilot. Nice.
With that, we’ve successfully automated away playing a fun game. Yay? This strategy works for any word, and hones in on it extremely quickly.
All the code can be found on Github.